1. 메서드 이름으로 쿼리 생성
2. 메서드 이름으로 JPA NamedQuery 호출
3. @Query 애노테이션을 사용해서 Repository 인터페이스에 쿼리 직접 정의
메서드 이름으로 쿼리 생성
스프링 데이터 jpa 맛보기할 때 잠깐 봤던 내용이다.
회원을 조회하는 메서드가 존재한다고 가정해보자. 이 메서드는 이름과 나이를 매개변수로 받아 이름이 동일하고 매개변수로 들어온 나이보다 더 많은 회원을 조회한다.

순수한 JPA를 사용하여 메서드를 만든다면 다음과 같이 만들 수 있다.

하지만 스프링 데이터 jpa를 사용한다면 구현없이 위와같이 메서드 인터페이스를 만드는 것만으로도 끝이난다.
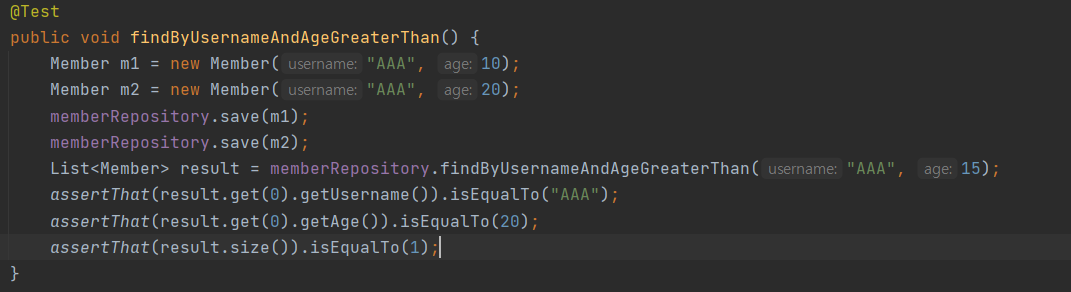

테스트 또한 성공하는 것을 확인할 수 있다.
어떻게 이것이 가능한 것인지 살펴보자.
findBy을 보고 스프링 데이터 jpa는 무언가 조회하는 메서드인 것을 인지한다. 그 후, findBy뒤인 UsernameAndAgeGreaterThan을 보게되는데, username과 age로 조회를 하고 이를 and조건으로 묶는다. 그리고 greaterthan을 보고 해당 age보다 큰 값을 조회한다는 것을 인지해 알아서 구현 메서드를 구현해준다.
실제 로그에 찍혀있는 쿼리를 살펴보면 아래와 같다.

이것은 관례적으로 스프링 데이터 jpa에 지정되어 있는 형식이기 때문에 변형하면 알아보지 못한다.
ex: findByUsername2AndAgeGreaterThan으로 하면 오류
또한 조건이 추가되면 메서드 명이 너무 길어진다는 단점이 존재한다.
사용 가능한 필터 조건은 아래 공식문서에서 확인이 가능하다.
https://docs.spring.io/spring-data/jpa/docs/current/reference/html/#jpa.query-methods.query-creation
Spring Data JPA - Reference Documentation
Example 109. Using @Transactional at query methods @Transactional(readOnly = true) interface UserRepository extends JpaRepository { List findByLastname(String lastname); @Modifying @Transactional @Query("delete from User u where u.active = false") void del
docs.spring.io
스프링 데이터 jpa가 제공하는 쿼리 메서드 기능
- 조회 : find...By, read...By, query...By, get..By
- 식별을 위해 ...에는 아무 단어나 들어가도 상관없음 ==> findHelloBy
- https://docs.spring.io/spring-data/jpa/docs/current/reference/html/#repositories.query-methods.query-creation
Spring Data JPA - Reference Documentation
Example 109. Using @Transactional at query methods @Transactional(readOnly = true) interface UserRepository extends JpaRepository { List findByLastname(String lastname); @Modifying @Transactional @Query("delete from User u where u.active = false") void del
docs.spring.io
- COUNT: count…By 반환타입 long
- EXISTS: exists…By 반환타입 boolean
- 삭제: delete…By, remove…By 반환타입 long
- DISTINCT: findDistinct, findMemberDistinctBy
- LIMIT: findFirst3, findFirst, findTop, findTop3
Spring Data JPA - Reference Documentation
Example 109. Using @Transactional at query methods @Transactional(readOnly = true) interface UserRepository extends JpaRepository { List findByLastname(String lastname); @Modifying @Transactional @Query("delete from User u where u.active = false") void del
docs.spring.io
간단한 쿼리를 만들 때는 유용, 복잡할 때는 사용하기 어려움
이 기능은 엔티티의 필드명이 변경되면 인터페이스에 정의한 메서드 이름도 꼭 함께 변경해야 한다. 그렇지 않으면 애플리케이션을 시작하는 시점에 오류가 발생한다. 애플리케이션이 뜨지 않음
이렇게 애플리케이션 로딩 시점에 오류를 인지할 수 있는 것이 스프링 데이터 JPA의 매우 큰 장점이다.
JPA의 NamedQuery 호출
사실 이 기능은 실제로 많이 사용되는 기능은 아니다.

엔티티 클래스에 위와 같이 NamedQuery 애노테이션을 사용하여 메서드 이름과 쿼리문을 직접 작성해준다.

이를 createNamedQuery 메서드를 사용해 불러와 사용하는데, 그냥 JPQL을 미리 지정해두고 불러와 사용하는 것으로 이해하면 될 것 같다.
테스트를 작성하여 실행시켜보니 아래와 같이 쿼리문이 잘 작성된 것을 확인할 수 있다.

이것은 개발자가 직접 구현을 해야하므로 번거롭다. 스프링 데이터 JPA는 이를 편리하게 사용할 수 있도록 지원해준다.

당연히 엔티티에 @NamedQuery가 지정되어 있어야한다. 구현의 번거로움없이 위와같이 인터페이스를 선언만 해줌으로써 완성할 수 있다. JPQL이 명확하게 명시되어 있고 파라미터가 필요하기 때문에 @Param을 사용하여 파라미터로 어떤 값이 들어가는지 알려준다.
스프링 데이터 JPA가 @Query를 보고 name을 통해 지정되어 있는 namedQuery를 찾는다. 그 namedQuery의 쿼리문을 실행하는 것이다.(@Param으로 파라미터 바인딩!)

테스트를 수행해보면 쿼리문이 앞에서 했던 것과 동일하게 잘 수행되는 것을 확인할 수 있다.
추가로 @Query를 주석처리하여도 정상 동작한다.

그 이유는?

관례상 스프링 데이터 jpa는 @Query가 없으면 엔티티 명과 메서드명을 기반으로 NamedQuery를 찾게된다.
엔티티명.메서드명과 같이 찾음. Member.findByUsername찾아서 NamedQuery가 만약 존재한다면 실행하고 없으면 메서드 명으로 쿼리를 생성하는 기능을 수행한다. 우선순위가 먼저 NamedQuery가 더 높다.
NamedQuery가 가지는 큰 장점 ==> 애플리케이션 load 시점에 쿼리문을 parsing하여 문법오류가 존재하면 오류 발생NamedQuery는 기본적으로 정적 쿼리이기 때문에 load 시점에 parsing이 가능함.
NamedQuery를 사용하지 않고 직접 JPQL을 작성할 때 실수로 문법 오류를 작성하여도 오류는 발생하지 않는다.

위와 같이 JPQL을 직접 작성하는 것은 문자이기 때문에 parsing이 불가능하다. 이 기능을 실제 호출하기 전까지는 오류가 있는지 없는지 알 수가 없다.
@Query, 리포지토리 메소드에 쿼리 정의하기

JPQL을 메서드 인터페이스에다가 바로 작성할 수 있다.
이 기능은 장점이 많기 때문에 실제로 사용성이 높다. JPQL을 바로 작성하기 때문에 메서드 이름으로 쿼리를 작성하는 기능처럼 메서드 이름을 복잡하게 하지 않아도 된다.
JPA NamedQuery 처럼 애플리케이션 실행 시점에 문법 오류를 발견할 수 있음(매우 큰 장점!)
이름이 없는 NamedQuery라고 생각하면 된다. 로딩시점에 모두 parsing하여 sql로 변환해놓는다. 이때 문법오류 발견
@Query - 값, DTO 조회하기
위에서는 엔티티 타입을 조회하였는데 값, DTO를 조회해보자.
회원 이름만 조회하기

DTO 조회하기


DTO 클래스를 만들고 JPQL에서 new를 사용하여 생성자와 매칭시켜준다. 마치 새로운 객체를 생성하여 반환하는 것 같은 효과를 내는 JPQL문법이다.
실제 실행되는 쿼리문을 살펴보면


Parameter Binding
1. 위치 기반
select m from Member m where m.username = ?0
2. 이름 기반
select m from Member m where m.username = :username
거의 이름 기반의 방법을 사용함 ==> 코드 가독성, 유지보수성
컬렉션 파라미터 바인딩

컬렉션도 파라미터로 바인딩이 가능하다.


반환 타입
컬렉션, Optional, 엔티티 등 여러 반환타입이 가능하다.



여기서 중요한 개념이 있다. 만약 컬렉션 조회를 할 때 존재하지않는 회원 이름으로 조회를 하면 어떻게 될까?
결과 컬렉션은 null일까? 그렇지 않다. 아무값이 조회되지 않아도 null이 반환되는 것이 아니라 빈 컬렉션이 반환된다!!
따라서 만약 아래와 같은 코드를 작성한다면 개발자가 의도한 대로 코드는 동작하지 않을 것이다.
// Repository에 저장된 회원은 minchul과 son 두명이라고 가정
List<Member> result = memberRepository.findListByUsername("kim");
if (result == null) {
System.out.println("존재하지 않는 회원입니다.);
}
else {
System.out.println("존재하는 회원입니다.");
}size가 0인 빈 컬렉션이 반환되기 때문에 조회되는 회원이 없더라도 null값이 아니다. 따라서 위와 같은 코드는 올바르지 않은 코드!!
하지만 단건 조회를 할 때는 null이 반환된다!!


또한 단건 조회를 할 때 반환되는 결과가 2건 이상이라면 NonUniqueResultException이 발생한다.(Optional도 마찬가지)
단건으로 지정한 메서드를 호출하면 스프링 데이터 JPA는 내부에서 JPQL의 Query.getSingleResult() 메서드를 호출한다. 이 메서드를 호출했을 때 조회 결과가 없으면 javax.persistence.NoResultException 예외가 발생하는데 스프링 데이터 JPA는 단건을 조회할 때 이 예외가 발생하면 예외를 무시하고 대신에 null 을 반환한다. 따라서 단건 조회때 null이 반환되는 것이다.
null 가능성이 있다면 깔끔하게 Optional을 사용하자!
가능한 반환타입은 아래 공식문서를 참조하자!
https://docs.spring.io/spring-data/jpa/docs/current/reference/html/#repository-query-return-types
Spring Data JPA - Reference Documentation
Example 109. Using @Transactional at query methods @Transactional(readOnly = true) interface UserRepository extends JpaRepository { List findByLastname(String lastname); @Modifying @Transactional @Query("delete from User u where u.active = false") void del
docs.spring.io
'Spring > Spring Data JPA' 카테고리의 다른 글
| @EntityGraph (0) | 2021.06.14 |
|---|---|
| 벌크성 수정 쿼리 (0) | 2021.06.14 |
| 페이징과 정렬 (0) | 2021.06.13 |
| Spring Data JPA 공통 인터페이스 (0) | 2021.06.10 |
| 스프링 데이터 JPA 맛보기 (0) | 2021.06.07 |